Almost every CIO I talk to boldly claims their enterprise is a “data-driven enterprise.” However, a recent Global CEO outlook by KPMG survey tells a completely different story: 67% of the CEOs worldwide (that number jumps to 78% in the US) suggest that they ignored the data-driven analytic and predictive models provided by their CIO/IT teams because it contradicted with their own experience; and they made major enterprise decisions based on their intuition.
CEOs who have overlooked data-driven insights to follow intuition instead
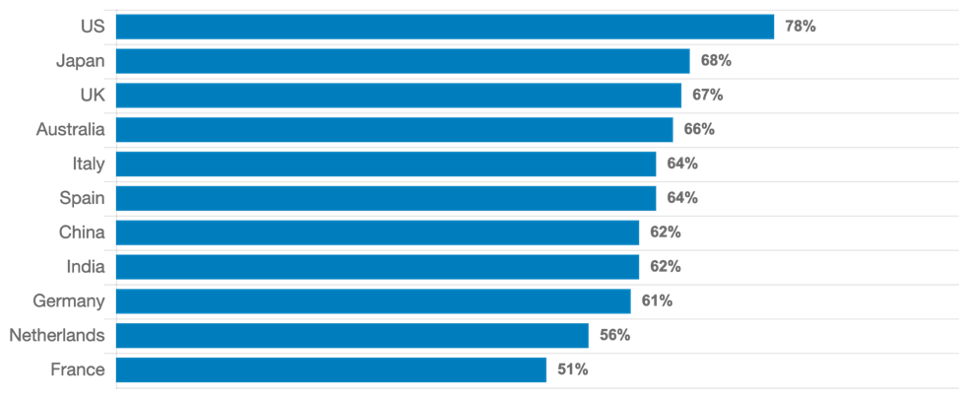
Source: 2018 Global CEO Outlook, KPMG International
While the results are somewhat shocking, it can be easily explained. Firstly, though the enterprises are producing more than enough data, the data is still very fragmented between BUs, domains, platforms, and implementations (such as cloud vs private data center). According to Forrester, up to 73% of company data is unused for analytics and insights. No wonder the CEOs were getting awful results with models that were produced by using only 27% of the total data! Secondly, most of the current predictive models use only the historic data and not the streaming (real-time) data. These two important factors lead to predictions without high accuracy. CEOs can’t make decisions if they can’t trust the models, as their business’s success or failure depends on the decisions they make.
More data leads to better predictions
Though it was IT Operations that kept the other enterprise AI initiatives running smoothly, implementing AI to better their own operations was slow. One reason for that was the fragmented data as above. When you feed AI/ML models with partial data, you will get only a partial view of the enterprise. Another major reason is because most of the current AI/ML implementations are for innovation and are funded by BUs generally. Enterprises traditionally viewed IT as a cost center so they were not willing to spend money to improve the operations using AI. But, with a ton of data, and with the current pandemic producing even more unconnected remote data, that perception changed when it started to overwhelm the Ops teams. The IT Operations teams are reaching a tipping point, having too much data to handle, which is an ideal scenario for AI. This is a sweet spot for AI and ML. AI thrives on lots of data. In fact, the more data is fed to the AI algorithms, the better the models can be.
Traditionally, the IT operations teams have monitored IT infrastructure monitoring (ITIM) and network performance monitoring and diagnostics (NPMD) layers for many years. In the last decade, application performance management (APM) has helped to get a better visibility on a per-application basis. But even when all those systems indicate they are working normally, customers can still experience problems based on the location, type of connection (mobile/internet), type of cache/CDN provider used, etc. The complexity of modern applications and the components it loads into the customer view make it very complex. The concept of digital experience monitoring (DEM) has gained visibility to specifically monitor, analyze, and optimize the customer experience. However, these are more like monitoring tools than diagnostic tools.
AIOps (artificial intelligence in IT operations) solutions can help solve this problem. A good AIOps solution should be able to ingest data from multiple sources, eliminate noise, co-relate the event sequences, and produce actionable insights based on a combination of historic and real time data.
Data Collection
Arguably, this is the most important step. Not only does the historic data need to be fed to AI for model creation, but also the real time data needs to be fed to the AI for both inference as well as for updating the model. Just collecting logs or SNMP like the good old days is not going to give the full picture of the enterprise. Collect as much information as possible, including events, logs, time-series data, application data, performance data, utilization data, etc. Newer event-based paradigm shifts to pub/sub or event-based messaging. Though these messages are very hyper, they are absolutely critical in collecting real-time data to provide a complete view of the enterprise and to make accurate predictions. Most cloud-based systems, whether container or virtual machine-based, provide a wealth of information via APIs. Time series data from IoT devices and capacity and performance metrics from almost all hardware devices should be included as well.
Collect structured, semi-structured and unstructured data. While the existing BI and analytic systems struggle with unstructured data, AI loves it. It can parse pretty much anything from audio, video, text files, images, configuration files, documents, PDF files, etc.
Finally, most teams forget to include configuration records, change management systems, CMBD, etc. as part of the equation. This is especially important with agile teams that tend to push multiple release cycles per day at times. Unless the IT operations teams are aware of the recent changes, they will be wasting a lot of time trying to figure out the root cause of the problem.
Data Quality & Data Ingestion
AI has a data quality problem. The “Garbage In, Garbage Out” is very true while creating the AI/ML models. It doesn’t matter how good your algorithms are or how good your data scientists are; if you don’t feed it enough quality data, you will get nothing out of it. While enterprises collect a lot of data, it still is incomplete, incorrect, and/or inconsistent. You also need to collect the adjacent and related data as well. You might think they are irrelevant, but you will be surprised at what AI can find using data that is seemingly unrelated. An example is when the NASA satellite broke IBM’s AI engineers and NASA scientists found a way to figure out UV intensity using the brightness of the sun with 98% accuracy. I wrote an article on this recently, which can be seen here.
If you speak to a data scientist, they will tell you how much time they spend in preparing the data. As much as 80% of their time is spent in prepping the data instead of analyzing the data, or creating and fine-tuning the models.
Data Classification & Labelling
Data needs to be properly classified, categorized, and labeled for AI/ML to learn from it. This is especially true for supervised learning models. This is an important step before you can train, validate and tune your model. Accuracy and quality of labeling are two most important things. Accuracy measures how close the labeling is to ground truth, or how well it matches with your enterprise facts and/or real -world conditions. Quality is about the accuracy of labeling across the entire data set that is used for the models. This is especially true when you are using a combination of auto, outsourced, and in-house labeling work. Would all groups consistently label across the entire data set?
Data Cleansing
If an AI model is trained using biased data, it will undoubtedly produce a biased model. I wrote an article about how to avoid this and debias your data. Raw data can contain implicit bias information, such as racial, gender, origin, political, social, or other ideological biases. The only way to eliminate them would be to analyze for inequalities and to fix it before the model creation. If discriminatory practices are not eliminated from data, the model will be skewed towards producing biased results.
Data should only be included if it is from proven, authoritative, authenticated, and reliable sources. Data from unreliable sources should either be eliminated altogether, or it should be given lower confidence scores while fed to the model. Also, by controlling the classification accuracy, discrimination can be greatly reduced at a minimal incremental cost. This data pre-processing optimization should concentrate on controlling discrimination, limiting distortion in datasets, and preserving utility.
Data Repository
Given the volume, velocity and variety of data, the traditional on-site solutions for data storage and data management will not work for digital-native solutions. Many companies have resorted to data lake solutions to handle this problem. While a single centralized source of data can help, it needs to be properly secured, governed, and updated regularly. It should be able to seamlessly handle both structured and unstructured data.
Conclusion
AI needs data, lots of it. As my favorite character Johnny V (an AI based robot) from Short Circuit would say, “I need more input….” Make sure you are giving AI the right amount and quality of data if your executives are going to make major enterprise decisions based on that. If not, they will ignore your model outputs/recommendations and make their own decisions, thereby minimizing your value and eventually the funding you will get to digitize and improve your business.


No Comments
Leave a comment Cancel